 As data continues to play an increasingly important role in today’s business landscape, data teams are rapidly expanding to keep up with demand. According to recent trends, some of the top tech companies are approaching a data-to-engineers ratio of 1:2, reflecting the growing emphasis on data-driven decision-making.
As data continues to play an increasingly important role in today’s business landscape, data teams are rapidly expanding to keep up with demand. According to recent trends, some of the top tech companies are approaching a data-to-engineers ratio of 1:2, reflecting the growing emphasis on data-driven decision-making.
However, as Mikkel Dengsøe, a highly respected and experienced data leader, points out, more data people also means more complexity. In this blog post, we’ll examine the relationship between data team size and complexity, and explore some of the challenges that arise as data teams expand.
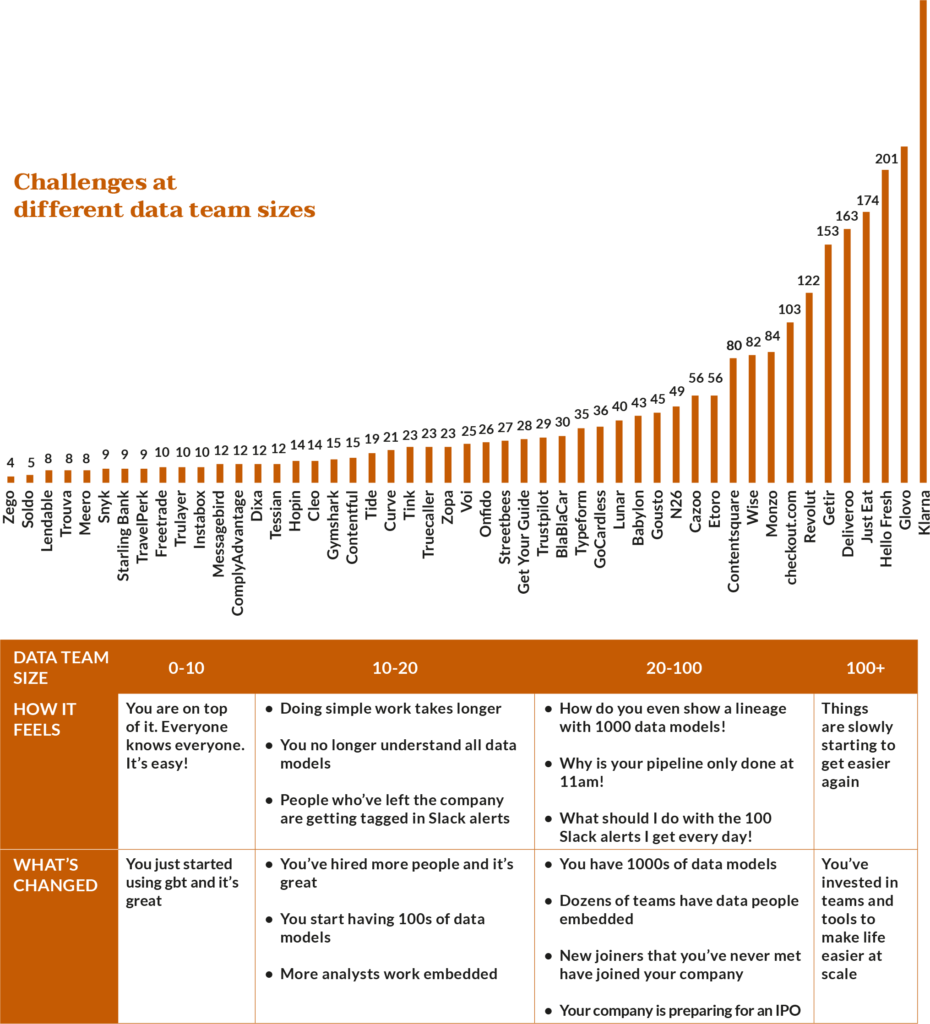
Data teams at high-growth companies are getting larger and some of the best tech companies are approaching a data-to-engineers ratio of 1:2.
More data people means more analysis, more insights, more machine learning models, and more data-informed decisions. But more data people also means more complexity, more data models, more dependencies, more alerts, and higher expectations.
When a data team is small you may be resource-constrained but things feel easy. Everyone knows everyone, you know the data stack inside out, and if anything fails you can fix it in no time.
But something happens when a data team grows past 10 people. You no longer know if the data you use is reliable, the lineage is too large to make sense of, and end-users start complaining about data issues every other day.
It doesn’t get easier from there. By the time the data team is 50 people you start having new joiners you’ve never met, people who have already left the company are still tagged in critical alerts, and the daily pipeline is only done by 11am leaving stakeholders complaining that data is never ready on time.
How did this happen?
With scale, data becomes exponentially more difficult.
(Image by the Author)
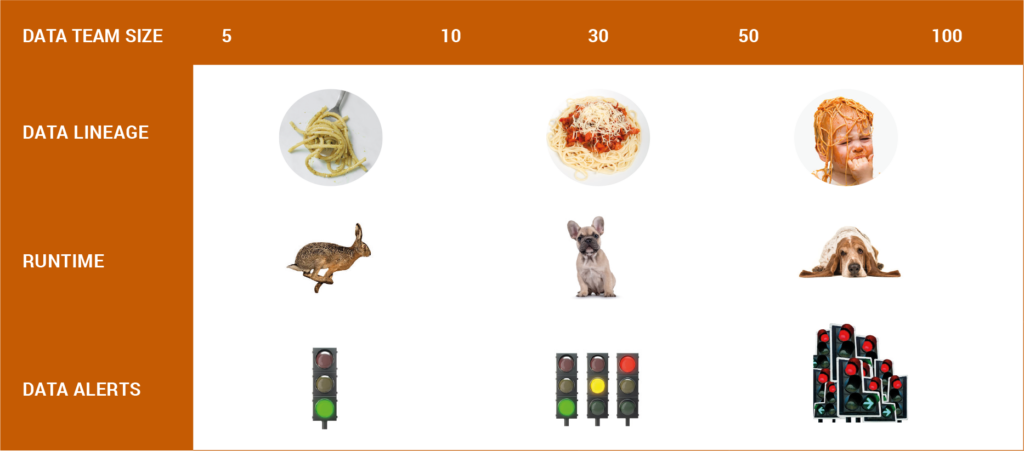
The data lineage becomes unmanageable. Visualising the data lineage is still the best way to get a representation of all dependencies and how data flows. But as you exceed hundreds of data models the lineage loses its purpose. At this scale you may have models with hundreds of dependencies and it feels more like a spaghetti mess than something useful. As it gets harder to visualise dependencies it also gets more difficult to reason about how everything fits together and knowing where the bottlenecks are.
The pipeline runs a bit slower every day. ou have so many dependencies that you no longer know what depends on what. Before you know it you find yourself in a mess that’s hard to get out of. That upstream data model with hundreds of downstream dependencies is made 30 minutes slower by one quirky join that someone made without knowing the consequences. Your data pipeline gradually degrades until stakeholders start complaining that data is never ready before noon. At that point you have to drop everything to fix it and spend months on something that could have been avoided.
Data alerts get increasingly difficult to manage. If you’re unlucky you’re stuck with hundreds of alerts, people mute the #data-alerts channel, or analysts stop writing tests altogether (beware of broken windows). If you’re more fortunate you get fewer alerts but still find it difficult to manage data issues. It’s unclear who’s looking at which issue. You often end up wasting time looking at data issues that have already been flagged to the upstream engineering team who will be making a root cause fix next week.
The largest data challenge is organisational. With scale you have teams that operate centrally, embedded and hybrid. You no longer know everyone in the team, in each all-hands meeting there are many new joiners you’ve never heard of, and people you have never met rely on data models you created a year ago andconstantly come to you with questions. As new people join they find it increasingly difficult to understand how everything fits together. You end up relying on the same few data heroes who are the only ones that understand how everything fits together. If you lose one of them you wouldn’t even know where to begin.
(Image by the Author)
All of the above are challenges faced by a growing number of data teams. Many growth companies that are approaching IPO stage have already surpassed a hundred people in their data teams.
How to deal with data teams at scale is something everyone is still trying to figure out. Here are a few of my own observations from having worked in a data team approaching a hundred people.
Embrace it. The first part is accepting that things get exponentially harder with scale and it won’t be as easy as when you were five people. Your business is much more complex, there are exponentially more dependencies and you may have regulatory scrutiny from preparing for an IPO or from regulators that you didn’t have before.
If things feel difficult that’s okay and they probably should.
Work as if you were a group of small teams. The big problem when teams scale is that the data stack is still treated as everyone’s responsibility.
As a rule of thumb a new joiner should be able to clearly see data models and systems that are important to them but more importantly know what they don’t have to pay attention to. It should be clear which data models from other teams you depend on. Some data teams have already started making progress on only exposing certain well-crafted data models to people outside their own team.
Don’t make all data everyone’s problem. Some people thrive from complex architectural-like work such as improving the pipeline run time. But some of the best data analysts are more like Sherlock Holmes and shine when they can dig for insights in a haystack of data.
Avoid mixing these too much. If your data analysts spend 50% of their time debugging data issues or sorting out pipeline performance, you should probably invest more in distributing this responsibility to data engineers or analytics engineers who shine at (and enjoy) this type of work.
Growing data teams are here to stay, and we’ve only scratched the surface of how we should approach this.