 Andreu Mora is SVP of Engineering at Adyen, where he’s responsible for data (platform, ML, AI, experiments and analytics). Andreu’s prior roles include VP of Engineering for Data Science and ML. Andreu has also held roles as Tech Lead, Data Scientist, and Engineer where he worked on products relating to network-based pattern recognition and scalable time series forecasting. Andreu holds an MSc in Telecommunication Engineering from Universitat Politecnica de Catalunya.
Andreu Mora is SVP of Engineering at Adyen, where he’s responsible for data (platform, ML, AI, experiments and analytics). Andreu’s prior roles include VP of Engineering for Data Science and ML. Andreu has also held roles as Tech Lead, Data Scientist, and Engineer where he worked on products relating to network-based pattern recognition and scalable time series forecasting. Andreu holds an MSc in Telecommunication Engineering from Universitat Politecnica de Catalunya.
In this post, Andreu explores the different factors involved in choosing the right tech stack for your business. Citing a real-world example, Andreu shares his insights learned from implementing the new ‘feature store’ at Adyen:
The point is, choosing what to buy and when to buy it is quite transcendental. Choosing your tech stack is a similar problem. You need to understand and reflect very well on a number of things:
● Whether you actually need it – or is it just a fun, exciting, but limited-value exercise (hello ChatGPT demos)?
● How do you sweep and track the market and assess which tool or framework to adopt?
● Should you build or buy?
● How fast do you need it and whether you are sacrificing something instead?
Without thorough consideration of the above, a leadership team (often proud of their choice and/or invested in another way) may spiral the team downwards in terms of productivity and motivation. That’s why it’s important to choose your tech stack with the right amount of love, and eventually make a well-informed choice together with the technical experts.
It is remarkably difficult if you end up in a situation where there’s a clear need for something better than what you have now, but there is no industry standard or a clear choice. That’s where my shopper-persona would collapse. The feature store, or should I say platform (will come onto that later), has been a primary example of this sort of conundrum.
At Adyen we have gone through this exercise a number of times, and in some cases we’ve learned the hard way in how to go about these choices. It really boils down to two things that we embrace in our ethos: iterating and control.
Our First Attempt At Building A Feature Store
Let me use an example of a use case for a feature store at Adyen. Every payment that goes through Adyen – and we do a lot of those ($860 billion in 2022) – undertakes a journey. This is where a number of decisions are made through an inference service, fueled by a machine learning model that we have trained and deployed. We have a few instances of those services with different purposes: our risk system (is the transaction fraud or legit), our authentication service (should we authenticate the user, and if so in which way), our routing algorithm, our transaction optimiser, our retry logic and others.
We are talking about a service that can take several thousand requests per second per model, and respond in less than 100 milliseconds. The final goal of all these models is to land as many good transactions as possible in the most efficient way, without ending up in a chargeback, a retry, or higher costs.
These models need features. They need features both at training time and at scoring time.
Let’s zoom in on the risk system. The service was initially built through rules across three different data sources:
● Block/allow look-up-tables, powered by PostgreSQL.
● Velocity database, powered by PostgreSQL, and able to provide information such as how many times has this card been used in this last minute.
● Our “shopper” database, also powered by PostgreSQL.
The ‘shopper’ database deserves its own paragraph. We have used, and maybe even abused, PostgreSQL in a very beautiful way; to identify shoppers in real time. This system ultimately provides an elegant and simple graph algorithm by identifying communities of attributes (such as cards and emails) that relate to the same person. It does that very efficiently and very quickly, but it has its own complications around flexibility and scalability. My colleague Burak wrote a great article about it. [1]
When we introduced a new approach based on a supervised classifier, we thought “hey, let’s include features about the merchant, that’ll boost AUCPR”.
To note, a merchant in fintech jargon is a seller or a company such as Uber or Spotify. In this instance we’d include (as a feature), datapoints such as the size of the merchant, the country of the merchant, how long have we been processing for this merchant, the authorisation rate of that merchant across different sliding windows and so on.
However, many of these example features are slowmoving, medium cardinality and have high data volume. PostgreSQL wasn’t going to cut it in terms of crunching all that volume.
We added a new database called ‘feature store’ (read that as Dr. Evil with his famous quotation mark hand gesture).
We took advantage of the fact that we were sending all our transaction events to our Big Data Platform via Kafka. We collected all of this info in the form of Hive tables and then we use Spark to crunch the information; all beautifully orchestrated through Airflow. We had all of this information and tooling available in our Big Data Platform because that’s where we train our models. We just need to use an abstraction layer to define the features (we chose Feast) and then deploy on another posgresql instance in the real-time flow. We love PostgreSQL, in case you haven’t figured this out yet. The ML artifacts are deployed to our real-time platform through our wrapper around MLflow, called Alfred, that allows us to stage their rollout into ghost, test, canary live settings and default live modes.
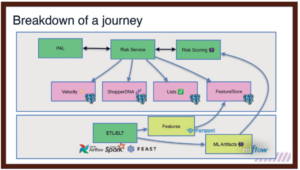
The final picture from our first crack at a ‘feature store’ looks like this.
THE BUILD-VS-BUY TRADEOFF
Hidden in all of this is something that might have passed unnoticed. The redux of a very important lesson that we have learned through the years: our build-vs-buy trade-off.
There are great vendors that promise and deliver a seamless turn-key experience that’s fast and just works. It’s a very amenable choice, and I can only show my honest respect for these startups. They are like rain in the middle of a drought for a lot of companies that want to instantly get in the gig of feature stores, MLOps, Experimentation, Data Governance and any other sweet problem to solve. And they do a good job at it.
At Adyen, we like to stay in control and understand what happens under the hood. We also have a very solid principle – we won’t use a vendor for anything touching our core business. In this case, processing a payment is indeed core business and we don’t want to introduce a dependency on a third-party. That has two important implications that are worth calling out:
● Firstly, we do use vendors, but we are critical about which part of the system they impact. On the one hand we buy our laptops from a vendor – it wouldn’t be optimal if we had a team building laptops. On the other hand, because we are set in building for the long term, we believe in controlling all our supply-chain (take SpaceX, who procure their own screws).
● Secondly, If we don’t use vendors, then do we build in-house? We have made that choice in the past, and now in perspective, it was a mistake. Picture a top-performing engineer, machete in their teeth, mumbling a classic “hold my beer”, and then proceeding to build, from scratch, something that already exists because “it will only take me a week to do it better”.
● We have been there and after the first month, I can guarantee the fun is over. Looking ahead at the feature parity roadmap leaves you in despair; the operational debt and preventable bugs itch you more than usual, and you end up going to bed every night thinking “why did we do this?”.
Iterating On The Feature Store
I already gave away one part of our ethos, which is based on strong control of our dependencies, fueled by longterm thinking. A second big trait of our way of thinking is the iteration culture.
At some point building software, and even hardware, someone figured out that working in waterfall contracts doesn’t really help. Instead, working in an agile way gets you further and faster, and it’s also more fun. The point of agile is not to adopt scrum. The point of agile is to embrace that the MVP is minimal (and therefore rusty and barely presentable) and also viable (it works, it’s not a WIP commit), and from there onwards, you have to quickly iterate.
We took a cold look at what we had proudly built as the feature store, tried to remove any emotional attachments to it, and ended up concluding that it wasn’t actually great. We also concluded that we might want to do some soul-searching and write a requirement list about what we want the whole thing to do.
We ended up with a letter to Santa detailing everything we wanted. At least from there, we could make a conscious choice about what we will not get given the cost and possibilities:
● Feature parity: the features and values on the training and scoring flows must be identical.
● Retrieval latency: we need the inference service to work under 100 ms.
● Recency: the features should not be old and we should be able to refresh them quickly.
The New Blueprint
Based on this, we also saw the need to have a system that spans two different platforms; our real-time platform (where payments, KYC, payouts, refunds and financial interactions happen with the world), and our big data platform (where we crunch the data). That’s not a surprise given that you have a need in two very different flows – your inference flow in real-time and your training flow off-line.
We needed an abstraction layer that would glue both systems together, so we chose to keep on using Feast, the open source package that allows Data Scientists and Engineers to uniquely define features and ensure consistency across the two environments. We also evaluated LinkedIn’s Feather, but deemed it too opinionated and opted for the openness of Feast.
So what’s the answer? Well, open source. We use open source as much as possible to build our infra and rails, and then we build our core business on top. We also contribute merging PRs and adding new features that we found useful. At the end of the day, the internet runs on open source.
● Cardinality: we want to be able to store billions of features.
● Distributed: we need instances of the feature store around the world, because we process globally.
● Storage /scalability: our transaction volume grows quite a lot every year, and we build for two.
● Availability/uptime: we need the system to be there 99.9% of the time.
● Self-service: ideally we want Data Scientists to help themselves when prototyping and deploying new features.
● Complex calculation: some of these features can be complex to compute, which should be accepted.
● Feature diversity: it’d be great if we didn’t have to maintain three different databases and we just had one endpoint with all sorts of data inside.
After seeing that list, we thought “wow, it’s a long list”, but we also figured out there was an underlying difference between a pure storage place and a place where things are computed. That’s where we read Chip Huygen’s fantastic article on Feature Platforms. It was one of those ‘a-ha’ moments, when you can confidently say out loud that “we were building a feature platform, not a feature store”, and you can hear the non-existent triumphant music behind you.
The main difference lies in facilitating the computing of features, apart from the storing and serving which is captured under the definition of the feature store.
The general idea behind synching happening on two environments is that some features will be computed on the real time flow and stored on hot storage and synced back to the cold storage (big data platform). The slowmoving features will then be computed on the big data platform, stored there (cold storage) and synced to the hot storage for inference.
While the batch computation engine and storage were already there in Spark and Hive/Spark/Delta, we still had a few choices to make regarding the online flow. For stream computing, we use Apache Flink – but we can define that later. For the storage layer we hit a dilemma across a few contenders: Redis, Cassandra, Cockroach and sweet old PostgreSQL.
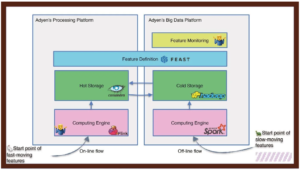
Here is where I will circle back to where I started. You need to make good decisions, and that probably means you need to involve technical experts. Even then, you also want to be able to tap into the wider organisation to make sure that you are not biased or forgetting anything. That’s why we have a TechRadar procedure where engineers can share ideas for technology contenders, spar, benchmark and eventually decide on which to adopt.
We decided on Cassandra. Redis’ in-memory storage makes it quite expensive at the cardinality we are looking for; Cockroach is really keen on readwrite consistency at the expense of speed; and well, PostgreSQL didn’t cut it for our needs.
We are still evaluating choices for online computing engines (as said, Flink looks good) and feature monitoring where it might be that we just use the monitoring stack available. This largely consists of Prometheus, Elastic and Grafana.
That’s an honest look at where we are today. We are making an informed choice and not shooting from the hip. We have determined what we need, and we have also determined what is important to us and what we are willing to pay for. We have analysed the market and open-source offering and are back to our beloved execution mode.
Even if there’s no clear and obvious choice, my shopper persona is still happily going through this procurement journey and enjoying the benefits of learning, discovering the possibilities and deciding. Because if we don’t get it right at first, we will build, fail, learn and iterate.